

SELECT first_name, last_name, (SELECT count(*) FROM film_actor fa WHERE fa.actor_id = a.actor_id) FROM actor a
It “forces” the database engine to run a nested loop of the form (in pseudo code):
|
1
2
3
4
5
6
7
|
for (Actor a : actor) { output( a.first_name, a.last_name, film_actor.where(fa -> fa.actor_id = a.actor_id) .size()} |
So, for every actor, collect all the corresponding film_actors and count them. This will produce the number of films each actors has played in.
It appears that it would be much better to run this query in “bulk”, I.e. to run:
|
1
2
3
4
5
|
SELECT first_name, last_name, count(*)FROM actor aJOIN film_actor fa USING (actor_id)GROUP BY actor_id, first_name, last_name |
But is it really faster? And if so, why would you expect that?
Bulk aggregation vs nested loops
Bulk aggregation in this case really just means that we’re collecting all actors and all film_actors and we then merge them in memory for the group by operation. The execution plan (in Oracle) looks like this:
------------------------------------------------------------------- | Id | Operation | Name | A-Rows | ------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 200 | | 1 | HASH GROUP BY | | 200 | |* 2 | HASH JOIN | | 5462 | | 3 | TABLE ACCESS FULL | ACTOR | 200 | | 4 | INDEX FAST FULL SCAN| IDX_FK_FILM_ACTOR_ACTOR | 5462 | -------------------------------------------------------------------
There are 5462 rows in our film_actor table, and for each actor, we join and group and aggregate them all to get to the results. Let’s compare this to the nested loop’s plan:
----------------------------------------------------------------------- | Id | Operation | Name | Starts | A-Rows | ----------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 200 | | 1 | SORT AGGREGATE | | 200 | 200 | |* 2 | INDEX RANGE SCAN| IDX_FK_FILM_ACTOR_ACTOR | 200 | 5462 | | 3 | TABLE ACCESS FULL| ACTOR | 1 | 200 | -----------------------------------------------------------------------
I’ve now included the “Starts” row to illustrate that after having collected all the 200 actors, we start the subquery 200 times to get the count for each actor. But this time, with a range scan.
From the plan only, can we tell which one is faster? Bulk aggregation will need more memory (to load all the data), but has a lower algorithmic complexity (linear). Nested looping will need less memory (all the required info is available from the index directly) but seems to have a higher algorithmic complexity (quadratic).
Fact is, this isn’t exactly true.
The bulk aggregation is indeed linear, but according to O(M + N) where M = number of actors and N = number of film_actors, whereas nested looping isn’t quadratic, it’s O(M log N). We don’t need to traverse the entire index to get the count.
At some point, the higher complexity is worse, but with this little amount of data, it’s not:
On the x-axis is the size of N and on the y-axis is the “complexity value”, e.g. how much time (or memory) is used by an algorithm.
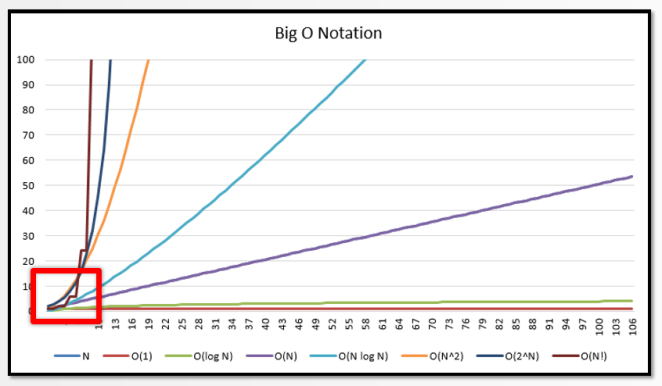
Effects of algorithmic complexity for large N

Effects of algorithmic complexity for “small” N
Here’s a disclaimer about the above:
Algorithmic complexity for “small N” = “works on my machine”

There’s nothing better than proving things with measurements. Let’s run the following PL/SQL program:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
SET SERVEROUTPUT ONDECLARE v_ts TIMESTAMP; v_repeat CONSTANT NUMBER := 1000;BEGIN v_ts := SYSTIMESTAMP; FOR i IN 1..v_repeat LOOP FOR rec IN ( SELECT first_name, last_name, (SELECT count(*) FROM film_actor fa WHERE fa.actor_id = a.actor_id) FROM actor a ) LOOP NULL; END LOOP; END LOOP; dbms_output.put_line('Nested select: ' || (SYSTIMESTAMP - v_ts)); v_ts := SYSTIMESTAMP; FOR i IN 1..v_repeat LOOP FOR rec IN ( SELECT first_name, last_name, count(*) FROM actor a JOIN film_actor fa USING (actor_id) GROUP BY actor_id, first_name, last_name ) LOOP NULL; END LOOP; END LOOP; dbms_output.put_line('Group by : ' || (SYSTIMESTAMP - v_ts));END;/ |
After three runs, and against our standard Sakila database (get it here: https://github.com/jOOQ/jOOQ/tree/master/jOOQ-examples/Sakila) with 200 actors and 5462 film_actors, we can see that the nested select consistently outperforms the bulk group by:
Nested select: +000000000 00:00:01.122000000 Group by : +000000000 00:00:03.191000000 Nested select: +000000000 00:00:01.116000000 Group by : +000000000 00:00:03.104000000 Nested select: +000000000 00:00:01.122000000 Group by : +000000000 00:00:03.228000000
Helping the optimiser
Some interesting feedback by Markus Winand (author of http://sql-performance-explained.com) was given on Twitter:

|
1
2
3
4
5
6
7
8
|
SELECT first_name, last_name, cFROM actor aJOIN ( SELECT actor_id, count(*) c FROM film_actor GROUP BY actor_id) USING (actor_id) |
which produces a slightly better plan than the “ordinary” group by query:
-------------------------------------------------------------------- | Id | Operation | Name | A-Rows | -------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 200 | |* 1 | HASH JOIN | | 200 | | 2 | TABLE ACCESS FULL | ACTOR | 200 | | 3 | VIEW | | 200 | | 4 | HASH GROUP BY | | 200 | | 5 | INDEX FAST FULL SCAN| IDX_FK_FILM_ACTOR_ACTOR | 5462 | --------------------------------------------------------------------
Adding it to the benchmark as such:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
SET SERVEROUTPUT ONDECLARE v_ts TIMESTAMP; v_repeat CONSTANT NUMBER := 1000;BEGIN v_ts := SYSTIMESTAMP; FOR i IN 1..v_repeat LOOP FOR rec IN ( SELECT first_name, last_name, (SELECT count(*) FROM film_actor fa WHERE fa.actor_id = a.actor_id) FROM actor a ) LOOP NULL; END LOOP; END LOOP; dbms_output.put_line('Nested select : ' || (SYSTIMESTAMP - v_ts)); v_ts := SYSTIMESTAMP; FOR i IN 1..v_repeat LOOP FOR rec IN ( SELECT first_name, last_name, count(*) FROM actor a JOIN film_actor fa USING (actor_id) GROUP BY actor_id, first_name, last_name ) LOOP NULL; END LOOP; END LOOP; dbms_output.put_line('Group by : ' || (SYSTIMESTAMP - v_ts)); v_ts := SYSTIMESTAMP; FOR i IN 1..v_repeat LOOP FOR rec IN ( SELECT first_name, last_name, c FROM actor a JOIN ( SELECT actor_id, count(*) c FROM film_actor GROUP BY actor_id ) USING (actor_id) ) LOOP NULL; END LOOP; END LOOP; dbms_output.put_line('Group by in derived table: ' || (SYSTIMESTAMP - v_ts));END;/ |
… shows that it’s already very close to the nested select option:
Nested select : +000000000 00:00:01.371000000 Group by : +000000000 00:00:03.417000000 Group by in derived table: +000000000 00:00:01.592000000 Nested select : +000000000 00:00:01.236000000 Group by : +000000000 00:00:03.329000000 Group by in derived table: +000000000 00:00:01.595000000
Conclusion
We have shown that under some circumstances, correlated subqueries can be better than bulk aggregation. In Oracle. With small-medium sized data sets. In other cases, that’s not true as the size of M and N, our two algorithmic complexity variables increase, O(M log N) will be much worse than O(M + N).
The conclusion here is: Don’t trust any initial judgement. Measure. When you run such a query a lot of times, 3x slower can make a big difference. But don’t go replace all your bulk aggregations either.
Liked this article? The content is part of our Data Geekery SQL performance training




